

Notice: We are working full time work on Runtime, the successor to NVM for Windows.
Updates will also be posted on the Author Software LinkedIn Page.
This is not the same thing as nvm! (expand for details)
The original nvm is a completely separate project for Mac/Linux only. This project uses an entirely different philosophy and is not just a clone of nvm. Details are listed in Why another version manager? and what’s the big difference?.






 |
 |
||


|
|||
|
Can’t sponsor? Consider nominating @coreybutler for a Github star. |
|||
| We’re working on Runtime (rt), the successor to NVM For Windows. Please contribute by taking a minute to complete this form. Thank you! |
Manage multiple installations of node.js on a Windows computer.
tl;dr Similar (not identical) to nvm, but for Windows. Has an installer. Download Now!
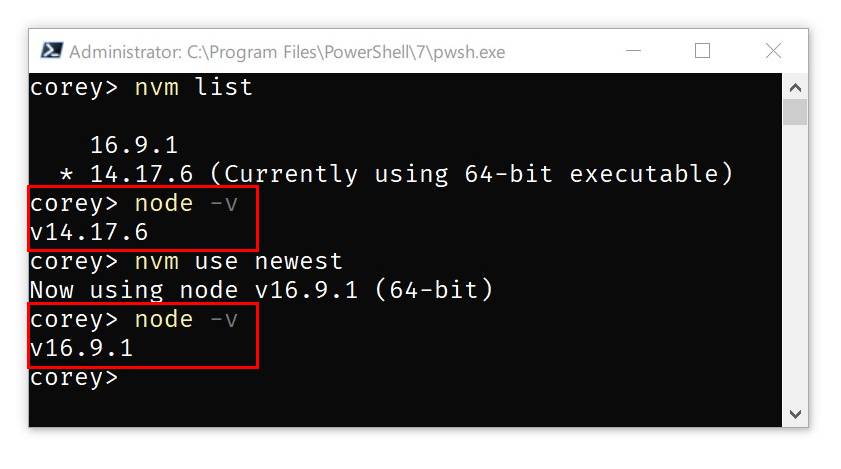
This has always been a node version manager, not an io.js manager, so there is no back-support for io.js. Node 4+ is supported. Remember when running nvm install or nvm use, Windows usually requires administrative rights (to create symlinks). To install the latest version of Node.js, run nvm install latest. To install the latest stable version, run nvm install lts.

There are situations where the ability to switch between different versions of Node.js can be very useful. For example, if you want to test a module you’re developing with the latest bleeding edge version without uninstalling the stable version of node, this utility can help.

The simplest (recommended) way to get NVM for Windows running properly is to uninstall any prior Node installation before installing NVM for Windows. It avoids all of the pitfalls listed below. However; you may not wish to nuke your Node installation if you’ve highly customized it. NVM for Windows can assume management of an existing installation, but there are nuances to this (dependent entirely on the permissions of the user running the installation). If you have an administrative account, it’s relatively safe to install NVM for Windows before uninstalling the original Node version. If you are working in a closed environment, such as a corporate Active Directory environment where installations/uninstallations are controlled by group policy, you should really consider removing the original version of Node before installing NVM4W.
Permission Problems For security reasons, Windows will not allow an application from one vendor to “uninstall” an application from a different vendor. The official NVM4W installer will attempt assume management of an existing installation of Node., but it cannot actually uninstall the original Node.js version. To work around this, NVM for Windows installer attempts to copy the original Node.js installation files to the NVM root. This includes global npm modules and configurations. Once this process is complete, the original Node.js installation can be uninstalled without losing data.
PATH Installation Problems
If you attempt to configure the NVM_SYMLINK to use an existing directory (like C:\Program Files\nodejs), it will fail because a symlink cannot overwrite a physical directory. This is not a problem if you choose a different symlink path (such as C:\nvm\node).
PATH Conflicts
If you do not uninstall the original version, running nvm use may appear to do nothing at all. Running node -v will always show the original installation version. This is due to a PATH conflict that presents when the same application is installed multiple times. In NVM4W 1.1.11+, run nvm debug to determine if you have a PATH conflict.
For simpliciy, we recommend uninstalling any existing versions of Node.js before using NVM for Windows. Delete any existing Node.js installation directories (e.g., %ProgramFiles%\nodejs) that might remain. NVM’s generated symlink will not overwrite an existing (even empty) installation directory.
👀 Backup any global npmrc config 👀
(e.g. %AppData%\npm\etc\npmrc)
Alternatively, copy the settings to the user config %UserProfile%\.npmrc. Delete the existing npm install location (e.g. %AppData%\npm) to prevent global module conflicts.
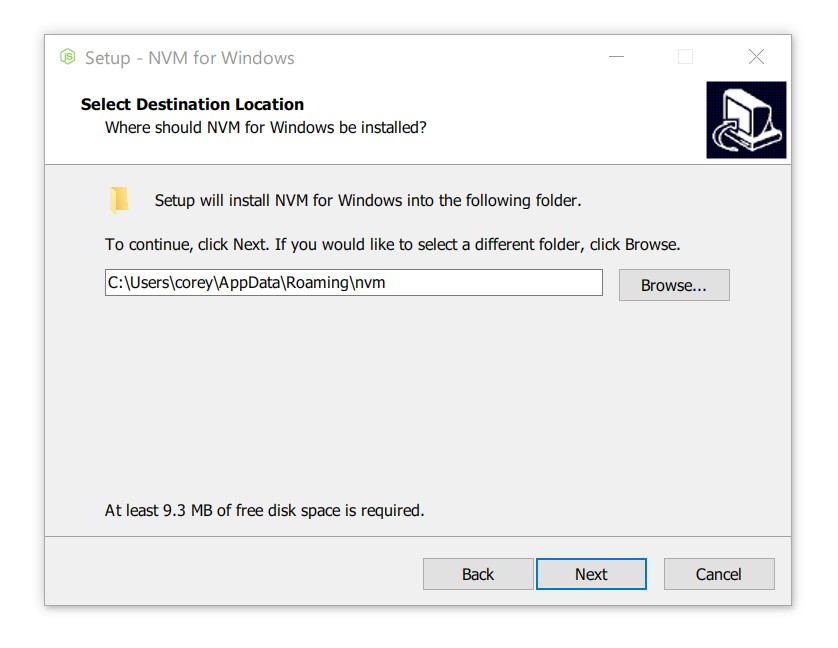
Use the latest installer (comes with an uninstaller). Alternatively, follow the manual installation guide.
If NVM4W doesn’t appear to work immediately after installation, restart the terminal/powershell (not the whole computer).

After install, reinstalling global utilities (e.g. yarn) will have to be done for each installed version of node:
nvm use 14.0.0
npm install -g yarn
nvm use 12.0.1
npm install -g yarn
💡 As of v1.1.8, there is an upgrade utility that will automate the upgrade process.
To upgrade nvm-windows, run the new installer. It will safely overwrite the files it needs to update without touching your node.js installations. Make sure you use the same installation and symlink folder. If you originally installed to the default locations, you just need to click “next” on each window until it finishes.
nvm-windows runs in an Admin shell. You’ll need to start powershell or Command Prompt as Administrator to use nvm-windows
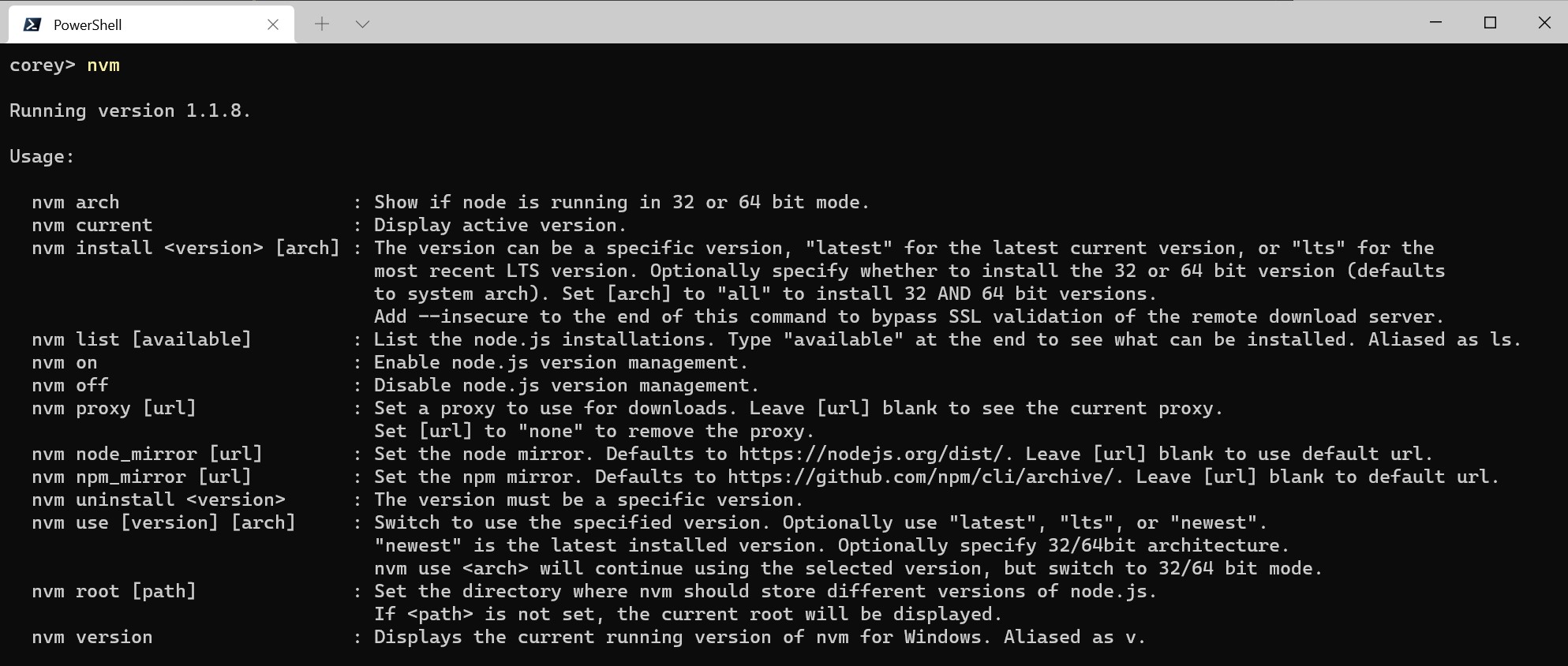
NVM for Windows is a command line tool. Simply type nvm in the console for help. The basic commands are:
nvm arch [32|64]: Show if node is running in 32 or 64 bit mode. Specify 32 or 64 to override the default architecture.nvm debug: Check the NVM4W process for known problems.nvm current: Display active version.nvm install <version> [arch]: The version can be a specific version, “latest” for the latest current version, or “lts” for the most recent LTS version. Optionally specify whether to install the 32 or 64 bit version (defaults to system arch). Set [arch] to “all” to install 32 AND 64 bit versions. Add--insecureto the end of this command to bypass SSL validation of the remote download server.nvm list [available]: List the node.js installations. Typeavailableat the end to show a list of versions available for download.nvm on: Enable node.js version management.nvm off: Disable node.js version management (does not uninstall anything).nvm proxy [url]: Set a proxy to use for downloads. Leave[url]blank to see the current proxy. Set[url]to “none” to remove the proxy.nvm uninstall <version>: Uninstall a specific version.nvm use <version> [arch]: Switch to use the specified version. Optionally uselatest,lts, ornewest.newestis the latest installed version. Optionally specify 32/64bit architecture.nvm use <arch>will continue using the selected version, but switch to 32/64 bit mode. For information about usingusein a specific directory (or using.nvmrc), please refer to issue #16.nvm root <path>: Set the directory where nvm should store different versions of node.js. If<path>is not set, the current root will be displayed.nvm version: Displays the current running version of NVM for Windows.nvm node_mirror <node_mirror_url>: Set the node mirror.People in China can use https://npmmirror.com/mirrors/node/nvm npm_mirror <npm_mirror_url>: Set the npm mirror.People in China can use https://npmmirror.com/mirrors/npm/
Please note that any global npm modules you may have installed are not shared between the various versions of node.js you have installed. Additionally, some npm modules may not be supported in the version of node you’re using, so be aware of your environment as you work.
Users have reported some problems using antivirus, specifically McAfee. It appears the antivirus software is manipulating access to the VBScript engine. See issue #133 for details and resolution.
v1.1.8 is not code signed, but all other versions are signed by Ecor Ventures LLC/Author.io. This should help prevent false positives with most antivirus software.
v1.1.8+ was not code signed due to an expired certificate (see the release notes for reasons). v1.1.9 is code signed thanks to ajyong, who sponsored the new certificate.
tldr; npm i -g yarn
See the wiki for details.
- Install go from http://golang.org
- Download source / Git Clone the repo
- Change GOARCH to amd64 in build.bat if you feel like building a 64-bit executable
- Fire up a Windows command prompt and change directory to project dir
- Execute
go get github.com/blang/semver - Execute
go get github.com/olekukonko/tablewriter - Execute
build.bat - Check the
distdirectory for generated setup program.
There are several version managers for node.js. Tools like nvm and n only run on Mac OSX and Linux. Windows users are left in the cold? No. nvmw and nodist are both designed for Windows. So, why another version manager for Windows?
The architecture of most node version managers for Windows rely on .bat files, which do some clever tricks to set or mimic environment variables. Some of them use node itself (once it’s downloaded), which is admirable, but prone to problems. Right around node 0.10.30, the installation structure changed a little, causing some of these to just stop working with anything new.
Additionally, some users struggle to install these modules since it requires a little more knowledge of node’s installation structure. I believe if it were easier for people to switch between versions, people might take the time to test their code on back and future versions… which is just good practice.
First and foremost, this version of nvm has no dependency on node. It’s written in Go, which is a much more structured approach than hacking around a limited .bat file. It does not rely on having an existing node installation. Go offers the ability to create a Mac/Linux version on the same code base. In fact, this is already underway.
The control mechanism is also quite different. There are two general ways to support multiple node installations with hot switching capabilities. The first is to modify the system PATH any time you switch versions, or bypass it by using a .bat file to mimic the node executable and redirect accordingly. This always seemed a little hackish to me, and there are some quirks as a result of this implementation.
The second option is to use a symlink. This concept requires putting the symlink in the system PATH, then updating its target to the node installation directory you want to use. This is a straightforward approach, and seems to be what people recommend…. until they realize just how much of a pain symlinks are on Windows. This is why it hasn’t happened before.
In order to create/modify a symlink, you must be running as an admin, and you must get around Windows UAC (that annoying prompt). Luckily, this is a challenge I already solved with some helper scripts in node-windows. As a result, NVM for Windows maintains a single symlink that is put in the system PATH during installation only. Switching to different versions of node is a matter of switching the symlink target. As a result, this utility does not require you to run nvm use x.x.x every time you open a console window. When you do run nvm use x.x.x, the active version of node is automatically updated across all open console windows. It also persists between system reboots, so you only need to use nvm when you want to make a change.
NVM for Windows comes with an installer, courtesy of a byproduct of my work on Fenix Web Server.
Overall, this project brings together some ideas, a few battle-hardened pieces of other modules, and support for newer versions of node.
NVM for Windows recognizes the “latest” versions using a list provided by the Node project. Version 1.1.1+ use this list. Before this list existed, I was scraping releases and serving it as a standalone data feed. This list was used in versions 1.1.0 and prior, but is now deprecated.
I needed it, plain and simple. Additionally, it’s apparent that support for multiple versions is not coming to node core. It was also an excuse to play with Go.
I chose Go because it is cross-platform, felt like less overhead than Java, has been around longer than most people think. Plus, I wanted to experiment with it. I’ve been asked why I didn’t write it with Node. Trying to write a tool with the tool you’re trying to install doesn’t make sense to me. As a result, my project requirements for this were simple… something that’s not Node. Node will continue to evolve and change. If you need a reminder of that, remember io.js, Ayo, all the breaking changes between 4.x.x and 6.x.x, and the shift to ES Modules in 12+. Change is inevitable in the world of software. JavaScript is extremely dynamic.
Thanks to everyone who has submitted issues on and off Github, made suggestions, and generally helped make this a better project. Special thanks to
- @vkbansal, who provided significant early feedback throughout the early releases.
- @rainabba and @sullivanpt for getting Node v4 support integrated.
- @s-h-a-d-o-w who resolved the longstanding space escaping issue in path names (#355).
- ajyong who sponsored the code signing certificate in late 2021.

 https://github.com/coreybutler/nvm-windows
https://github.com/coreybutler/nvm-windows